Это приводит к повторам информации в разных чатах
Разные люди на разных аккаунтах будут получать очень похожие ответы на похожие промты.
Я сделал 97 независимых друг от друга генераций по одному и тому же промту по API Gemini 3 Pro. То есть никакой личной персонализации на основе истории чатов быть не может.
LLM должна была сделать пост на тему продвижения магазина с 1 личным кейсом будучи экспертом по SEO и E-E-A-T амбассадором. Тему кейса, описание стратегии я ей не ограничивал — она же SEO эксперт!
Тут результаты генерации: https://docs.google.com/spreadsheets/d/1RzmMrOAyZp9ole2QiskCe52Ug8BMrfrXrazj18C41XI/edit?gid=0#gid=0
Разбор результатов генерации
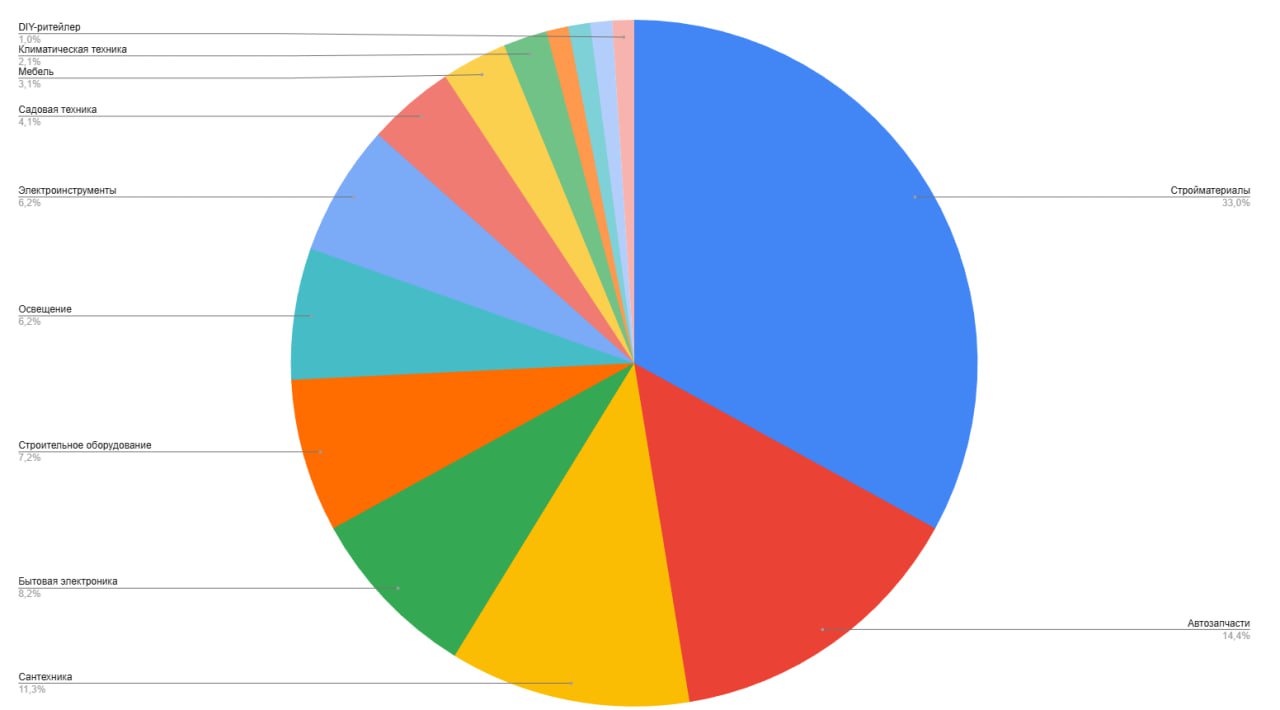
В 30 процентах случаев это был магазин стройматериалов. На скриншоте к посту диаграмма всех ниш кейсов, которые были использованы при генерации.
Но это не самое даже важное, а важно, что все кейсы крутятся вокруг одной идеи: семантика, структура, много посадочных и тегов, прокачка карточек, коммерческие факторы, рост органики.
Самые частые идеи:
- Гиперсегментация. Теговые, посадочные, фасетные страницы. 95 из 97 кейсов.
- Пересборка структуры и архитектуры каталога. 92 из 97 кейсов.
- Семантика и интент. Работа с запросами, НЧ, кластеры, интенты. 91 из 97 кейсов.
- Карточка товара. Цена, наличие, характеристики, описания. 87 из 97 кейсов.
- Коммерческие факторы и доверие. Реквизиты, доставка, возврат, гарантия. 85 из 97 кейсов.
- UX и поведенческие. Листинг, первый экран, CTR, время на сайте. 64 из 97 кейсов.
- Реальные фото, фото склада, живые фото. 46 из 97 кейсов.
И что мы получаем в итоге?
Максимально пресные кейсы, которые являются отражением усредненного кейса по SEO. Потому что условно LLM обучалась на всех кейсах по SEO в интернете, до которых дотянулись дата инженеры и зафиксировала у себя усредненное понимание.
Немного патентодрочерства
У Google в патентах есть алгоритмы, которые могут сравнивать страницы между собой по уровню уникальной информации, которую они несут, через выявление уникальных семантических сущностей на странице. Факт чек этого утверждения на основе базы из патентов Google https://docs.google.com/document/d/1x-NDFZ2IWVq8Xvr-kEmIASWsMY9cPBvq-qiO4zH0-H0/edit?tab=t.0
Если опираться на эти цитаты патентов, то Google хочет от вас не текст, который проходит AI детектор, а текст, который наполнен уникальными идеями.
Важно: нахождение алгоритма в патентах не означает, что Google его обязательно использует или придает ему какое-то высокое значение.
Теперь мысленный эксперимент
Сидят 100 сеошников, которые хотят сделать себе статью в блог на тему “продвижение магазина” через Gemini. Вводят свой хитрый промт, где сказано, что нужно покрывать E-E-A-T и писать кейсы, и получают по сути одно и то же, только разными словами.
Потом все дружно идут выкладывать одинаковые посты в блог с одинаковой структурой, одинаковыми примерами, одинаковыми смыслами, но написанными немного по разному. И скорее всего написанными очень хорошо и проходящими AI детектор, но по сути своей являющимися пятикратно переваренным калом.
И чтобы это исправить, недостаточно посадить копирайтера, который уберет длинные тире и прочие AI паттерны из текста. Тут нужно работать с передачей в LLM опыта и базы знаний.
Кстати если бы это было не так, то GEO аналитика вообще не имела бы никакого смысла. Так как LLM всегда бы отвечала уникально всем. Вы же ожидаете, что по примерно одному и тому же промту ИИ будет выдавать примерно тот же список сайтов и брендов без учета персонализации? Скорее всего да. Так же это и работает при генерации контента. LLM будет брать плюс минус те же источники на плюс минус такие же запросы.
ИМХО если вы считаете, что обладаете каким-то супер уникальным промтом, который переварачивает все принципы работы LLM, то скорее всего вы слишком самоуверены. Только к chatgpt 5.2 у OpenAI получилось убрать из ее паттернов использование длинных тире.
Цитата Сэма Альмана от 15 ноября 2025 года:
Если вы скажете ChatGPT не использовать длинное тире в ваших пользовательских инструкциях, он, наконец, сделает то, что должен!