Бегло сравнил DeepSeek v3.2 с «тир-1» моделями на задаче текстового анализа
Дисклеймер: Это небольшой тех-пример, а не полноценный валидный эксперимент. Результаты нельзя обобщать на все задачи. А тем более считать, что это какая-то реально рабочая задача или инструмент.
Что за задача
Нужно по одному поисковому запросу и интенту:
- выделить важные аспекты удовлетворения поискового интента на странице; Типа какие блоки нужны на странице.
- подобрать n-граммы (2–5 слов) к этим аспектам;
- выделить ядро темы — фразы, которые описывают всю страницу в целом.
Модель должна:
- Взять тексты конкурентов по запросу.
- Выделить из них аспекты темы.
- Из полу грязного списка ~1500+ n-грамм выбрать те, которые лучше всего описывают каждый аспект и формируют ядро темы.
По сути, задача на умение вытащить из большого текстового мусора только значимые фразы.
Как было реализовано
Пайплайн (упрощенный):
Вход:
• основной запрос;
• формулировка интента пользователя.
Сбор данных: парсинг страниц из топ-15 по запросу (FireCrawl, только основной контент), чистка кода, преобразование в текст.
N-граммы:
• небольшой код на собирает 2–5-граммы с конкурентов,
• чистит стоп-слова, мусор и цифры,
• считает TF/DF,
• отбрасывает фразы с слишком малым DF.
Вход в модель:
• интент,
• запрос,
• тексты конкурентов,
• CSV с ~1500 n-граммами и их DF/TF.
Этап очистки n-грамм очень легкий — хотел посмотреть, как модели ведут себя на «грязном» входе и на пределе контекста.
Для каждой модели одна и та же задача гонялась несколько раз, дальше я смотрел на разброс и формировал ожидания по качеству.
Конкретный пример
Тема: подбор SEO-агентства.
Цель анализа: понять критерии выбора агентства.
Данные: 5 лонгридов, ~1700 n-грамм.
Что ожидаем:
- ядро темы с n-граммами типа «выбрать агентство», «подбор агентства» и так далее
- +-10 аспектов типа: гарантии, цена, набор услуг, сроки, результаты, КП с распределенными фразами по ним.
Что на скриншоте
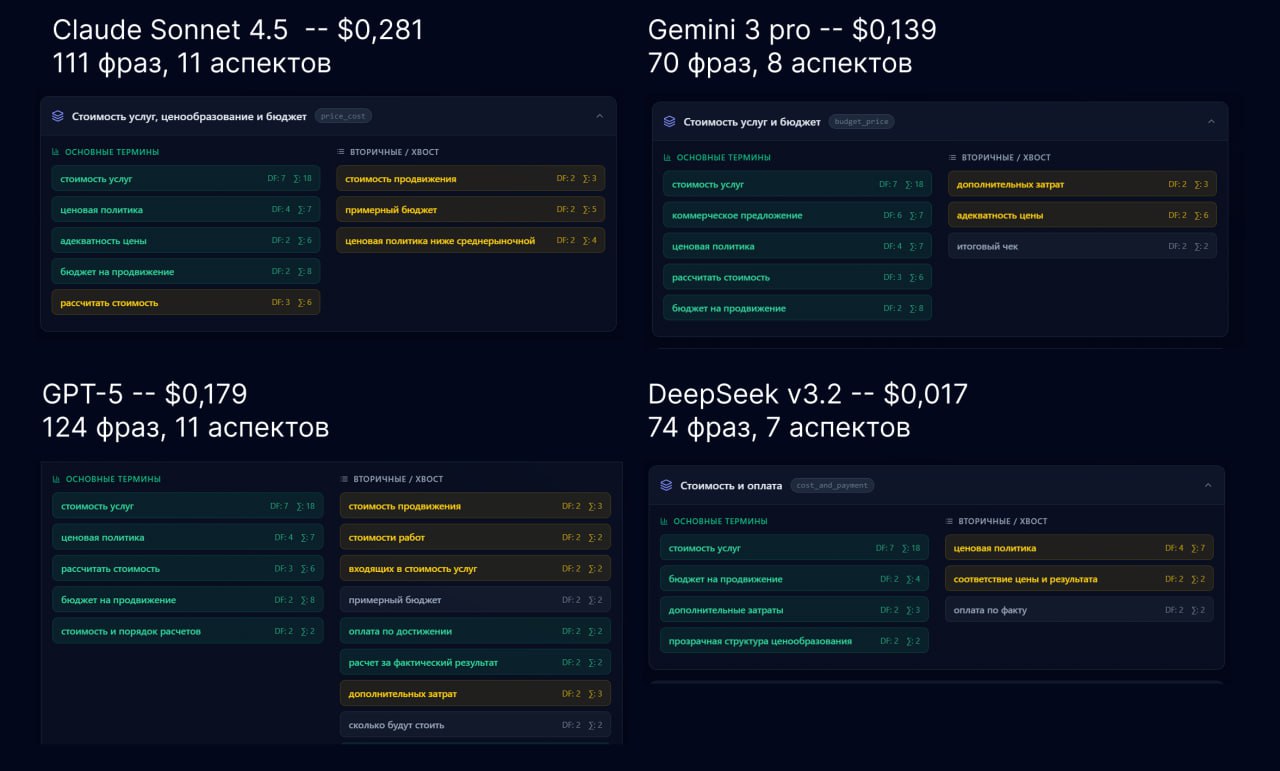
На скрине — один из типичных запусков по аспекту «Стоимость» для четырёх моделей:
• Claude Sonnet 4.5 — $0.281, 111 фраз, 11 аспектов
• Gemini 3 Pro — $0.139, 70 фраз, 8 аспектов
• GPT-5 — $0.179, 124 фразы, 11 аспектов
• DeepSeek v3.2 — $0.017, 74 фразы, 7 аспектов
Смотрим на три вещи:
- Цена одного прогона.
В этой задаче DeepSeek v3.2 оказался дешевле других в примерно 8–11 раз.
- Количество фраз и аспектов.
• По субъективному ощущению, GPT-5 и Claude вытащили больше релевантных фраз и аккуратнее разложили их по аспектам. Больше всего мне нравится работа Клода, но он и самый дорогой.
• Gemini и DeepSeek отработали заметно проще, но в рамках этой задачи — примерно на одном уровне.
• Само по себе число фраз/аспектов — не метрика качества, это просто дополнительный сигнал.
- Содержимое аспекта «Стоимость».
Я взял один блок (в среднем их 6–12 на запуск) и посмотрел, что модели туда относят.
• Все более-менее поймали основные вещи: «стоимость услуг», «ценовая политика», «бюджет на продвижение», «рассчитать стоимость» и т.п.
4. Содержимое ядра темы:
Сделал отдельный скрин с выделением основы темы https://skr.sh/sYuG7YOb56N (справа это Sonnet 4.5). Видно что если убрать фразы по «критериям выбора», то результат плюс минус одинаковый в них.
Выводы с поправкой на все ограничения эксперимента:
- DeepSeek v3.2 справляется с задачей «раскидать n-граммы по аспектам» достаточно адекватно и при этом стоит копейки относительно условных «тир-1» моделей.
- Если под него подточить предобработку (жёстче чистить n-граммы, делать многоступенчатый пайплайн) и разбить задачу на 2–3 шага, можно за очень небольшой бюджет получить результат, близкий к тому, что дают Claude / GPT на прямом решении.
Свои окончательные выводы по моделям делайте сами — я здесь всего лишь показал один конкретный сценарий использования модели и как в нём себя повёл DeepSeek по сравнению с «крутыми» моделями.